Our Approach
Future exascale architectures will face major challenges. In order to build something relevant to future applications running on exascale supercomputers, IO-SEA will follow a strict co- design approach. IO-SEA uses various HPC-oriented applications (called use cases in the document), from astrophysics to elementary particle physics, large-volume image processing and weather forecasting. These applications are extremely challenging in terms of IO workload and will define the requirements that will drive the development of the new solution. Those applications have been chosen for their “data greediness”, making them quite representative for future exascale simulation codes. The project will include several “demonstration checkpoints” where running the use cases will highlight the benefits obtained via the new architecture and give directions to continue the work.
Data workflow
Moving data between nodes is one of the most energy-hungry operations. Traditional HPC workflows, unfortunately, have a pattern of computing data, storing the results in the global storage system, loading the result data as an input for the next workflow stage and then computing again. The unnecessary store operations lead to increased data movement and decreased performance of the overall workflow. Today’s batch scheduling environments nevertheless do not understand the meaning of data and therefore have to schedule most stages of a workflow individually, making data movement a necessity.
Workflow execution will be significantly improved by IO-SEA by allowing users and applications to tag data and therefore to add information about its future usage as well as of the usage of resulting data.
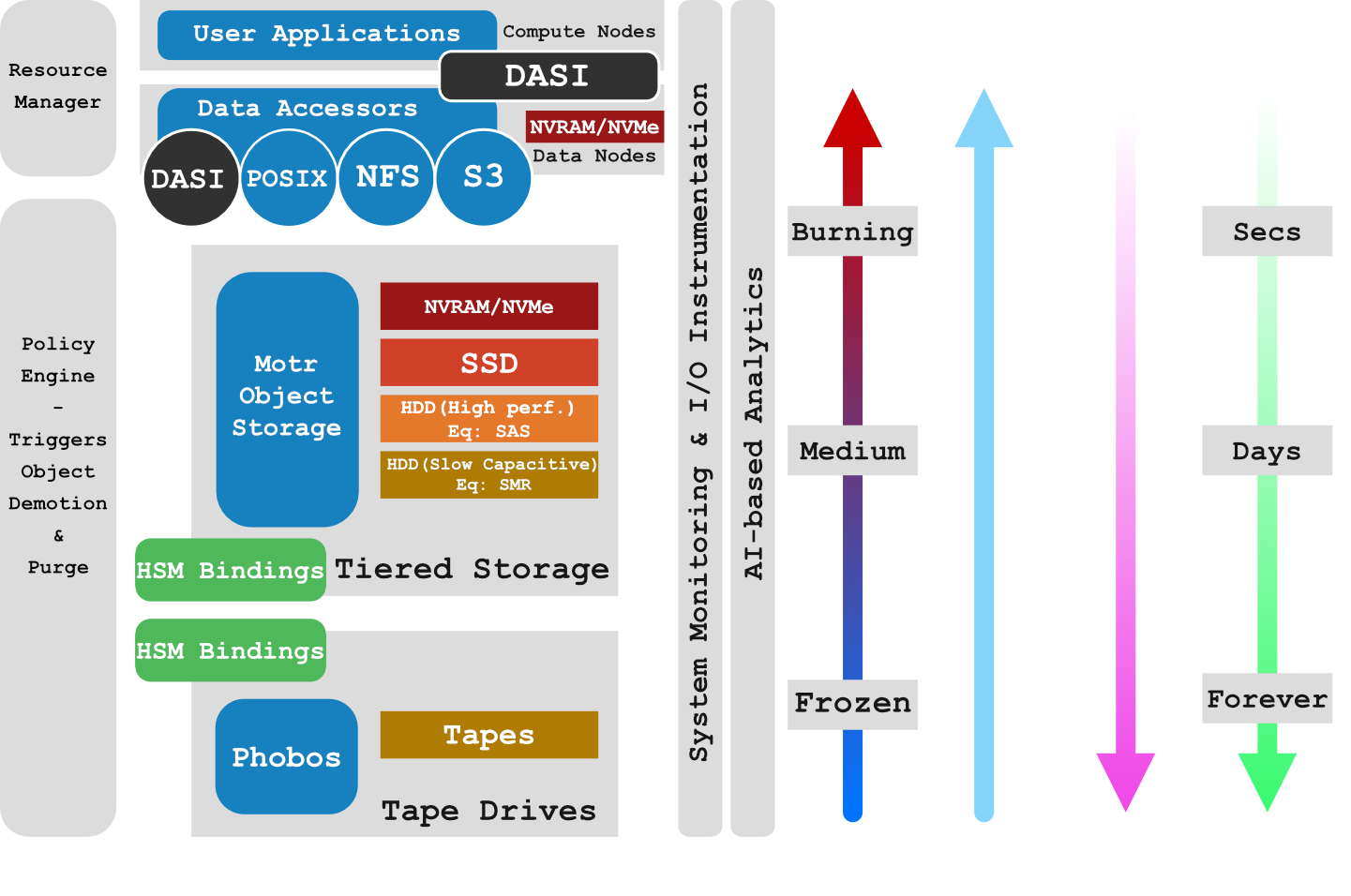
Instrumentation
Several IO instrumentation tools exist (Darshan, Mistral, etc). However, they are mostly targeted to application developers, to help understanding how IOs are generated by their applications in order to improve their code. The IO-SEA project will extend these tools to make it possible to build applications and workflows models. Those models will be focused on data creation and data consumption, identifying the data lifecycle, and will contain enough information to set up an optimal Data Centric IO run time environment for future executions. AI based analytics tools will complement instrumentation, analysing the behaviour of multiple workflow executions in order to evaluate their reproducibility and contribute planning the right resource allocation for future executions.
API
Exascale datasets are expected to feature complex structures and reach multiple PiB sizes. IO-SEA will design a Data Access and Storage application Interface (DASI) to abstract those structures from their actual storage form and tier location. To maximise runtime and energy efficiency, the interfaces will support data-centric workflows where data movements will be minimised and data processing performed preferably in-situ.The DASI will use a semantic description of the data for all its access and storage actions, thus enriching the workflow with domain knowledge and providing a meaningful data abstraction.
HSM
HSM (Hierarchical Storage Management) mechanisms are rare in object stores, very few of them are capable of dealing with storage tiers, and none can mix disks and tapes inside the same tier. The IO-SEA project will make it possible to use NVMe devices, HDD, SSD and tapes inside the same tier, thus providing what is needed to manage the complete data lifecycle inside the same system.