Use Cases: SBB At Work!
By Dr Eric B Gregory @ Juelich Supercomputing Centre
After two years of anticipation, the five IO-SEA scientific use cases have run their workflows in an IO-SEA environment installed on the DEEP system, home cluster of the DEEP-SEA project. Re-purposed hardware leftover from the SAGE2 project and given new, useful life as IO-SEA data nodes.
In the first versions of the IO-SEA Workflow Manager (WFM) there is a single ephemeral service, the Smart Burst Buffer, which intercepts I/O operations to or from a specific directory (and its sub-directories) on the background storage system.
When a full workflow is run with the SBB service, output data is buffered on the data node. If the data is re-used in subsequent workflow steps, it can be read from the SBB, economizing on data movements between the application and disk.

The figure, from the IO-Instrumentation report of a LQCD workflow, shows the data flow between compute nodes, the SBB and the back-end storage.
During the course of the workflow a lattice gauge field configuration file (1.2 GB) is read from disk. This gauge configuration in part defines a large, sparse linear system. Four solution vectors, called propagators, of this system are obtained with an iterative solver and written out with size 5.1 GB each.
In the final step of the workflow, the propagators are read in and combined in different pairs to calculate correlation functions used to calculate the mass of meson particles. Each propagator is read in twice, however we see from the figure all of the reads are coming from the data nodes and not the back-end storage.
This accounts for the difference between data read from SBB to compute nodes, and that moving deom teh disk to SBB:
8 * 5.14GB = 42.3GB – 1.2GB
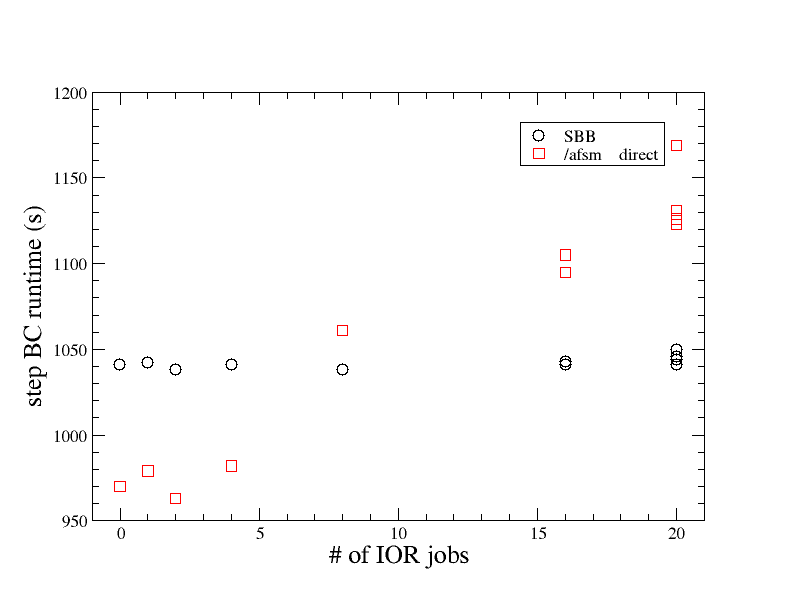
We were also able to see the SBB’s utility in the context of a very busy storage system. We ran the LQCD workflow with and without the SBB on the DEEP system. On other compute nodes we ran ran the IOR [https://github.com/hpc/ior] benchmark application, which writes and re-writes files to the back-end storage as quickly as possible.
In the figure below we see that as we increase the load on the file system with more instances of IOR, the runtime of the LQCD workflow with direct I/O to the back-end (AFSM) storage suffers proportionally. However, the workflows buffered through the data nodes are insulated from the disk traffic.
SBB at work!