Use case Lattice QCD: Particle physics on a supercomputer
What is the origin of the mass of objects around us? Why do experiments see the spectrum of particle masses that they do? Surprisingly, many of these questions are attacked by physicists not in particle accelerators, but on supercomputers using the methods known as Lattice QCD.
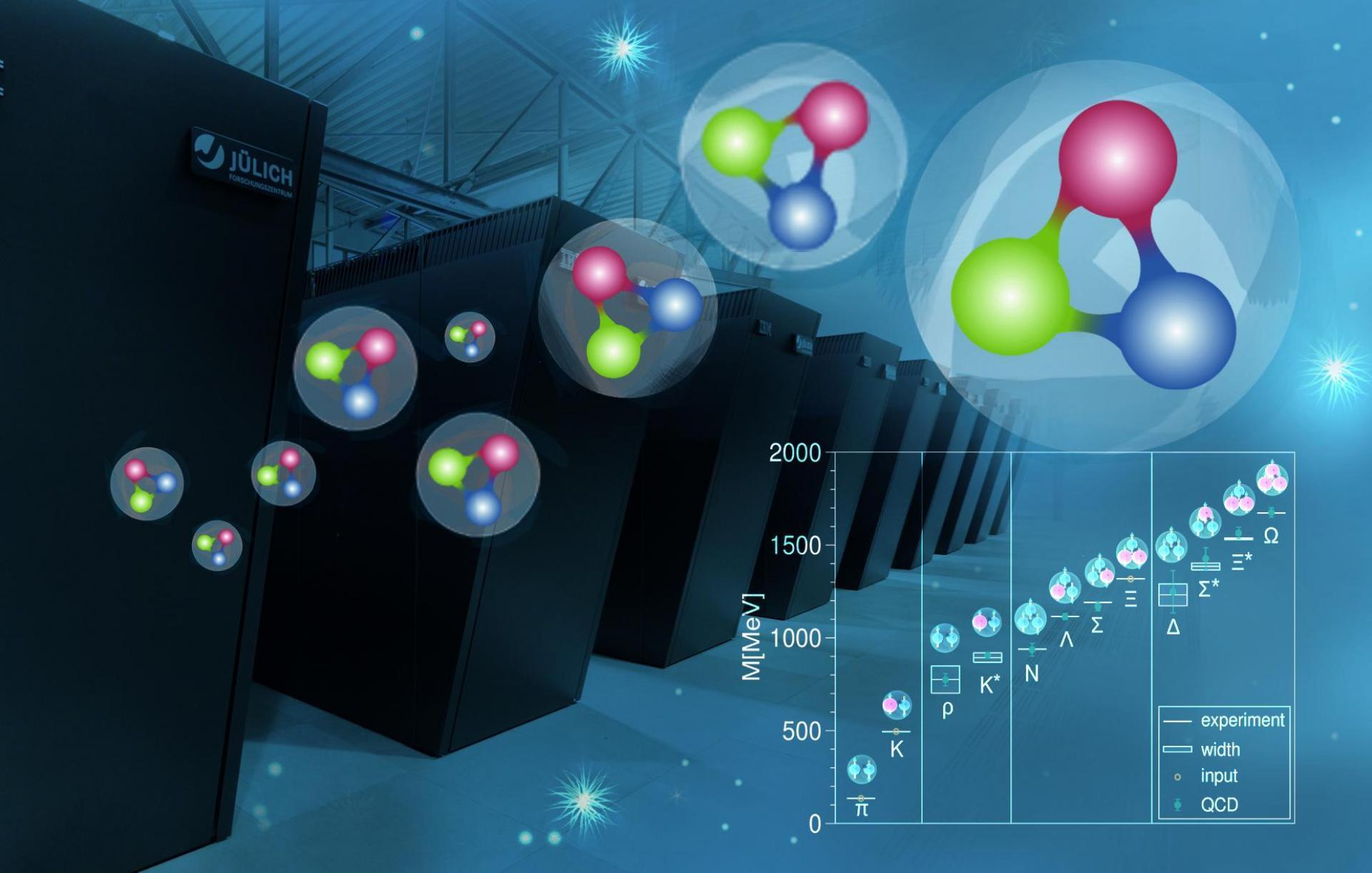
Matter is composed of a hierarchy of ever-smaller particles: molecules are composed of atoms, atomic nuclei contain protons and neutrons, and within the proton and neutron are fundamental particles called quarks.
At this level, physicists have a very successful theory, called the Standard Model of Particle Physics. The Standard Model relates fundamental particles to three of the four known fundamental forces: electromagnetism, the weak interaction, and the strong force. (Gravity, so far, defies a quantum description.)
A part of the Standard Model called quantumchromodynamics (QCD) describes the interaction of quarks with each other by the exchange of gluons, the carriers of the strong force. The theory of QCD can be written down in a concise expression, called the action, which is a function of quantum quark and gluon fields.
Calculating properties of hadrons — composite particles composed of quarks and gluons — is not so simple, however. We must take into account complex quantum fluctuations implied by the theory.
A very successful approach to these predictions is to simulate a finite, four-dimensional lattice populated with quark and gluon fields. One dimension represents time; the others are the three familiar spatial dimensions. Supercomputers are used to generate fluctuations of these fields, with the statistics of the fluctuations governed by the QCD Action. This approach is called Lattice QCD (LQCD).
The homogeneity of the problem, as well as hardware and algorithm improvements have allowed excellent scaling of LQCD to large problem sizes and tens of thousands of processes. The result is much smaller uncertainties on computed quantities, but much larger data challenges. How can I/O be better optimized? How can the many large data files be managed?
As one of the use cases of IO-SEA, these challenges will drive the co-design of IO-SEA solutions, as well as provide real-world tests of their eventual implementation.